Einführung
Bei der Programmierung in den „klassischen“ Programmiersprachen ist Modularisierung schon „ewig“ ein Thema. Die Entwicklung kennt viele Facetten wie objektorientierte oder funktionale Programmierung usw.
An der Datenbankentwicklung ging das alles irgendwie vorbei. Ja, die Datenbankentwicklung folgt einer anderen Logik. Die wird auch daran sichtbar, dass die Tools sehr lange keine Entwicklungstools waren, sondern mehr der in Richtung Administration tendierten.
Die Datenbankprojekte von Visual Studio eröffnen hier neue Möglichkeiten (Datenbankentwicklung mit VisualStudio). Eine Möglichkeit ist die Modularisierung, auch wenn sicherlich noch Wünsche unerfüllt bleiben.
Das Beispiel finden Sie als Download hier: Example_Logging.zip
Der Schlüssel – Datenbankreferenzen
Datenbankreferenzen können vielseitig eingesetzt werden. Hier betrachten wir die Möglichkeiten mit der Brille der Modularisierung.
Der Dialog zum Anlegen einer Datenbankreferenz sie wie folgt aus:
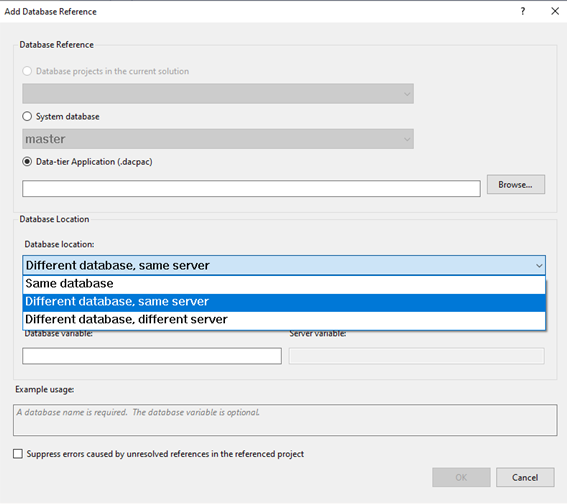
Wichtige Bemerkung: Die Referenzen müssen einen Baum sein, zyklische Abhängigkeiten sind nicht erlaubt!
Zur Modularisierung wird die Database Location: Same Database benutzt. Dabei wird der gesamte Code der referenzierten Datenbank Bestandteil der Datenbank, die die Referenz enthält.
Es ist Ihnen sicherlich aufgefallen, dass die Referenz ein Datenbankprojekt bzw. ein .dacpac ist. Damit ist klar, dass jedes Databankmodul für sich selbstständig sein muss. Beachten Sie dies insbesondere bei der Verwendung von Schemata.
Verwenden von Datenbankmodulen
Neben der Gliederung der aktuellen Entwicklung in kleinere Einheiten gibt immer wiederkehrende Funktionen, z.B. Logging, eigene Gruppierungsfunktionen usw.
Es ist logisch, dass man die Einheiten einer Entwicklung in einer Solution zusammenhält und die Referenzen auf der Ebene der Projekte durchführt.
Für globale Module ist dieses Vorgehen nicht sinnvoll, da dies mit der Vervielfachung von Code erreicht wird. Hier kommen die .dacpac ins Spiel. .dacpac werden während des Buildprozesses erstellt. Für die Verteilung kann NuGet verwendet werden. Dieses Thema werde ich einem weiteren Artikel getrennt behandeln.
Ein winziges Beispiel
Dieses Beispiel ist eine Illustration des Vorgehens und ist auf das allernotwendigste beschränkt.
Die Solution für das Beispiel hat folgende Struktur:
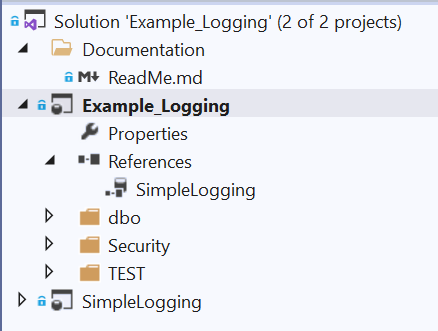
Example_Logging ist das Projekt der Gesamtlösung und enthält einen Verweis auf das Projekt SimpleLogging, welches die Logik des Loggings enthält.
Die Referenz auf das Projekt SimpleLogging wurde mit der Database Location Same Database erstellt und damit wird die gesamte Struktur von SimpleLogging ein Teil von Example_Logging.
Wird nun Example_Logging deployed (pulish), dann entsteht eine Datenbank mit folgenden Objekten:
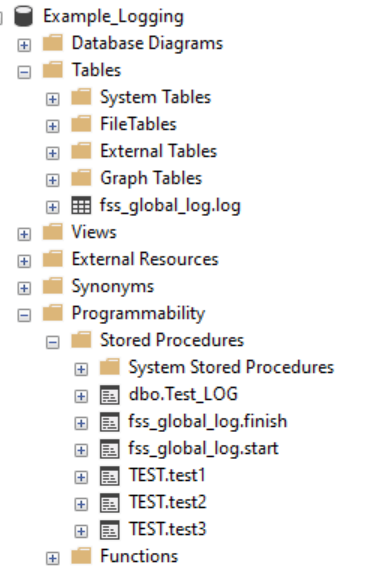
Alle Objekte des Schemas fss_global_log stammen aus dem Projekt SimpleLogging.
Beim Aufruf von dbo.Test_LOG werden Prozeduren aufgerufen und der Start und das Ende protokolliert.
Unser Ziel, eine Datenbank aus mehreren, logisch selbstständigen Projekten zu erstellen, haben wir erreicht.
Ausblick
Das hier gezeigte Vorgehen eignet sich, wenn die Teilprojekte sehr selten wiederverwendet werden. Wenn man das Teilprojekt in vielen anderen Projekten verwenden will, dann ist eine andere Lösung notwendig.
In einem weiteren Artikel werde ich zeigen, wie dies funktioniert.
